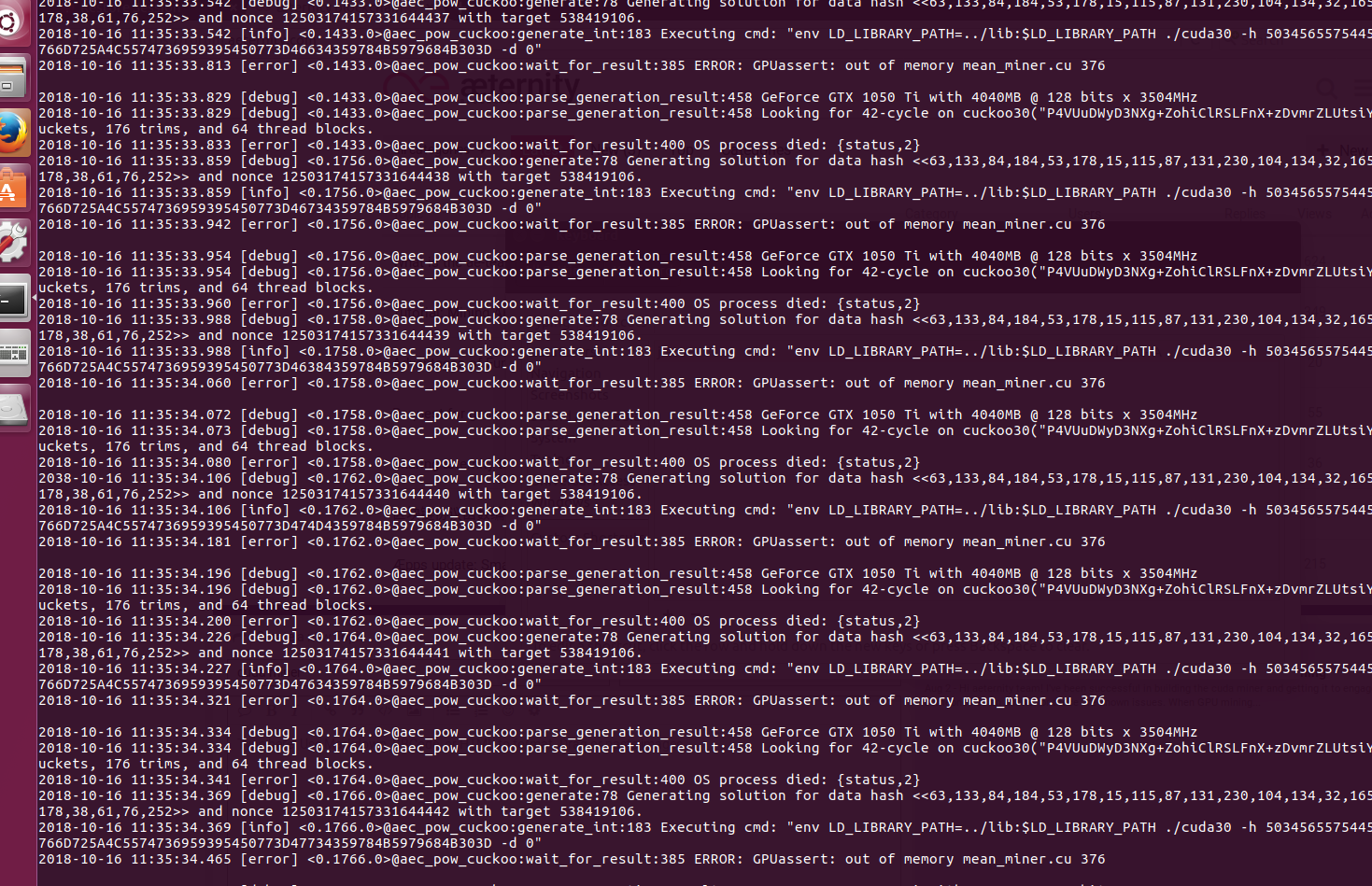
What is the format of the extra_args: “-d 0” to bring on multiple GPU’s. I can change the address and get different GPU’s to show the cuda30 process and memory usage on NVIDIA-SMI but can’t find out how to bring on the multiple GPU’s in the rig.
Another thing I am seeing is the memory usage and power of the GPU increase as I start the node and the CUDA30 process is shown. After running for a bit the process is not shown anymore and the memory usage goes way down but power stays up. Something is happening but not going to tackle that until I can get all the GPU’s to come online then I will dig through the log and try to figure out what is happening…stay tuned.
I have looked at John Tromps Gighub and there are many arguments to “tune” the GPU’s but I can’t see how to bring on multiple GPU’s. It is with the arguments line but everything I have tried has been a bust.
Any help would be greatly appreciated. If you need any further info just let me know and I will provide ASAP.
Unfortunately the cuckoo binary neither epoch support multi-GPU. You’re best bet so far would be running different epoch instances (installs) and configuring each to use it’s own GPU.
Doesn’t support multiple GPU’s??? That’s disappointing. Then the cuda-miner.md is VERY misleading and IMO needs to be updated to reality.
Cut and Paste from cuda-miner.md
Multiple GPU devices
The address of a GPU device used by the miner can be set with -d argument, for example to set device with address 0:
mining:
cuckoo:
miner:
executable: cuda30
extra_args: “-d 0”
node_bits: 30
hex_encoded_header: true
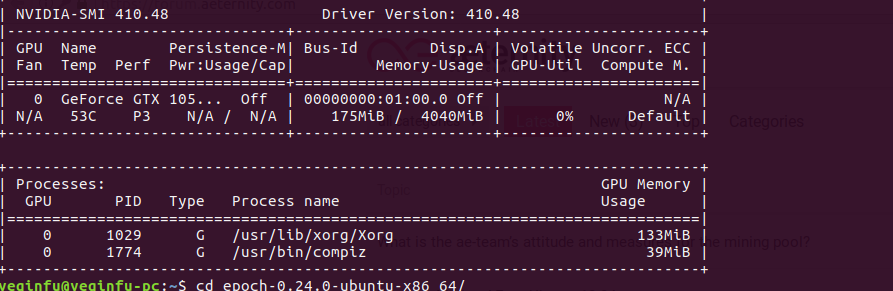
The address of the device can be obtained by running nvidia-smi
hey rob, it is a bit misleading, but that’s how its written on tromp’s github (the creator of cuckoo cycle pow algo), it’s just copied (in the same misleading manner :D)
you don’t need to copy paste the generated_keys. You need to configure the same beneficiary if you want to collect the reward in one (the same) account. As a side note, I’d suggest to keep out the beneficiary generated private key out of the mining node.
you should have separate installs with, one for each GPU. Not sure if I fully understand your question, but with that setup all GPU’s would compete for solution with each other.
Yes, you need more than 4GB VRAM (~5GB) with the default configuration which is optimised for speed. If you want to run with less memory - respectively with slower times, read the tunning guide and try playing with the parameters.
@ROB@gunray Not sure what’s misleading here. The docs are about the configuration changes and indeed the -d parameter changes the GPU device address. If you have multiple GPUs you can set which GPU instance the cuckoo miner should use.
@dincho.chain If my config is like this
···
miner:
executable: cuda30
extra_args: “”
node_bits: 30
···
is that mean the epoch only use GPU , and CPU mining is stop?